

Full Outer Join In Datastage
DataStage has three processing stages that can join tables based on the values of key columns: Lookup, Join and Merge. In this post, we discuss when to cull which stage, the difference betwixt these stages, and development references when nosotros use those stages.
Use the Lookup stage when:
- Having a small reference dataset.
- Doing a range lookup.
- Validating a row (If at that place is no corresponding entry in a lookup tabular array to the key's values, you tin can output the row in the pass up link).
Use the Join stage when:
- Joining large tables (y'all will run out of RAM with the Lookup stage).
- Doing outer joins (left, right, full outer).
- Joining multiple tables with the same keys.
Use the Merge stage when:
- Multiple update and reject links are needed (eastward.g. Combining a master data gear up with 1 or more update datasets)
Permit's discuss each stage in details.
Lookup Stage
Key Points
- The Lookup phase has a reference link, a unmarried input link, a single output link and a single rejects link.
- It does not required information on the input link or reference link to be sorted.
- Lookup stage is a in-retention processing stage. Large look up tabular array will result in the job failure if DataStage engine server runs out of retentivity.
- The Key cavalcade names in main and lookup tables practice non demand to be the aforementioned equally you lot map them in the stage.
- Make certain to select the right Lookup Stage Conditions (see Example step iii).
Development Reference
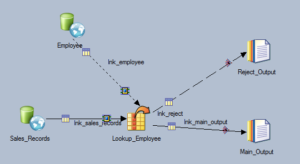
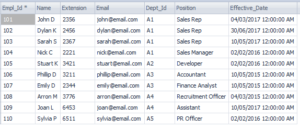
In this example, nosotros will add employees' information to the sales record by joining two table past the cardinal columns, Empl_Id
(1) Map the key column and map the output in the Lookup stage.
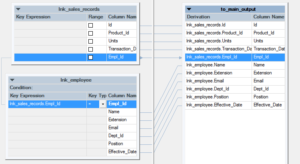
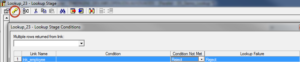
(two) Select Lookup Phase Conditions to specify the deportment when Lookup condition is non met and Lookup fails.
There are 4 options: Continue, Drop, Fail and Turn down.
- Continue: When the lookup table does not accept the value appears in the main table, it will assign null values to the lookup tabular array columns. In another word, this option works like Left Join.
- Drib: When the lookup table does not have the value appears in the main table, it will drop the row all together. In another discussion, this selection works similar Inner Bring together.
- Fail: When the lookup table does non accept the value appears in the main table, the task will fail. This is the default option for the Lookup stage.
- Drop: When the lookup tabular array does not have the value appears in the principal table, it will output to the decline output (as in this example).
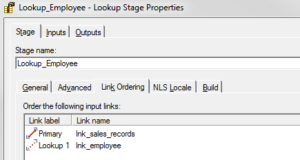
(3) Make sure you have the correct link guild.
(four) Input partitioning usually works with 'Auto'.
Join Stage
Central Points
- The cardinal columns must be the aforementioned name between tables.
- It tin can accept multiple input links (as long every bit table has the same key columns between them) and a unmarried output link.
- The performance of Join can be improved by fundamental-sorting information on input links ('Auto' partitioning mode is ordinarily fine).
- If the reference dataset is small-scale enough to fit in RAM, it is faster to use Lookup.
- There are four bring together options: inner join, left outer join, right outer join and full outer bring together.
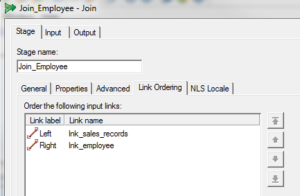
- We need to make certain input links are in the right order. This can be set from Stage -> Link Ordering.
Development Reference
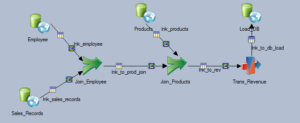
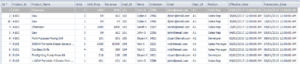
In this case, we join Employee and Products tables to Sales_Records based on Empl_Id and Product_Id. So, summate the revenue past multiplying the toll column from Products past the number of units sold.
(i) In each join stage, make sure to cull join key and blazon (Left outer, right outer, total outer, etc).
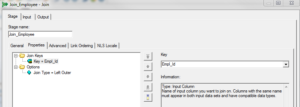
(2) Make sure the link order is correct.
(three) Partition can exist 'Automobile'.
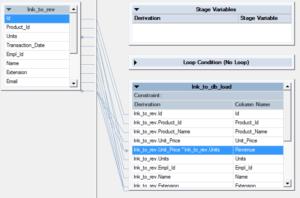
(4) Transformer Stage to calculate revenue by multiplying Unit_Price by Units. Notation that the data blazon for Units is integer and Unit_Price is double. Therefore, prepare the Revenue's data blazon as double.
Merge Phase
Key Points
- The Merge stage can have any number of input links, single output links and the aforementioned number of reject output links as the update input links.
- A primary record and an update record are merged only if both of them have the same values for the specified merged primal. In another word, merge phase does not exercise range lookup.
- To minimise memory requirements, we tin can ensure that rows with the aforementioned cardinal column values are located in the same sectionalisation and is processed in the same node by segmentation. However, the 'auto' option for sectionalisation usually works fine.
- As part of preprocessing, indistinguishable records need to exist removed from the master. If at that place are more than one update data sets, it only updates the first tape equally beneath.

Development Reference
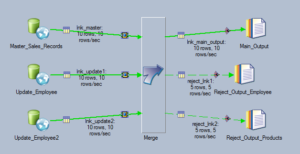
In this example, updating Master_Sales_Records with employee data from 2 reference Employee tables.
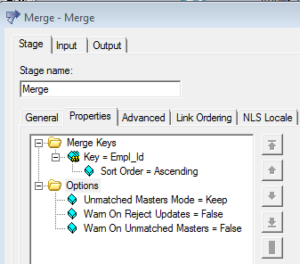
(ane) Merge stage has only three options, Unmatched Master Manner, Warn On Reject Updates and Warn On Unmatched Master. All the tables must have the aforementioned cavalcade names for the merge keys.
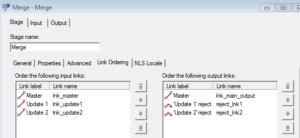
(2) Configure input and output links. Map them to the right link order.
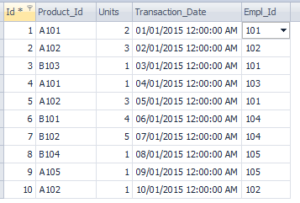
Reference Datasets
Sales_Records
Employee
Joined

Full Outer Join In Datastage,
Source: https://www.mydatahack.com/datastage-join-vs-lookup-vs-merge/
Posted by: johnstonyoulle.blogspot.com
0 Response to "Full Outer Join In Datastage"
Post a Comment